Curate Solutions
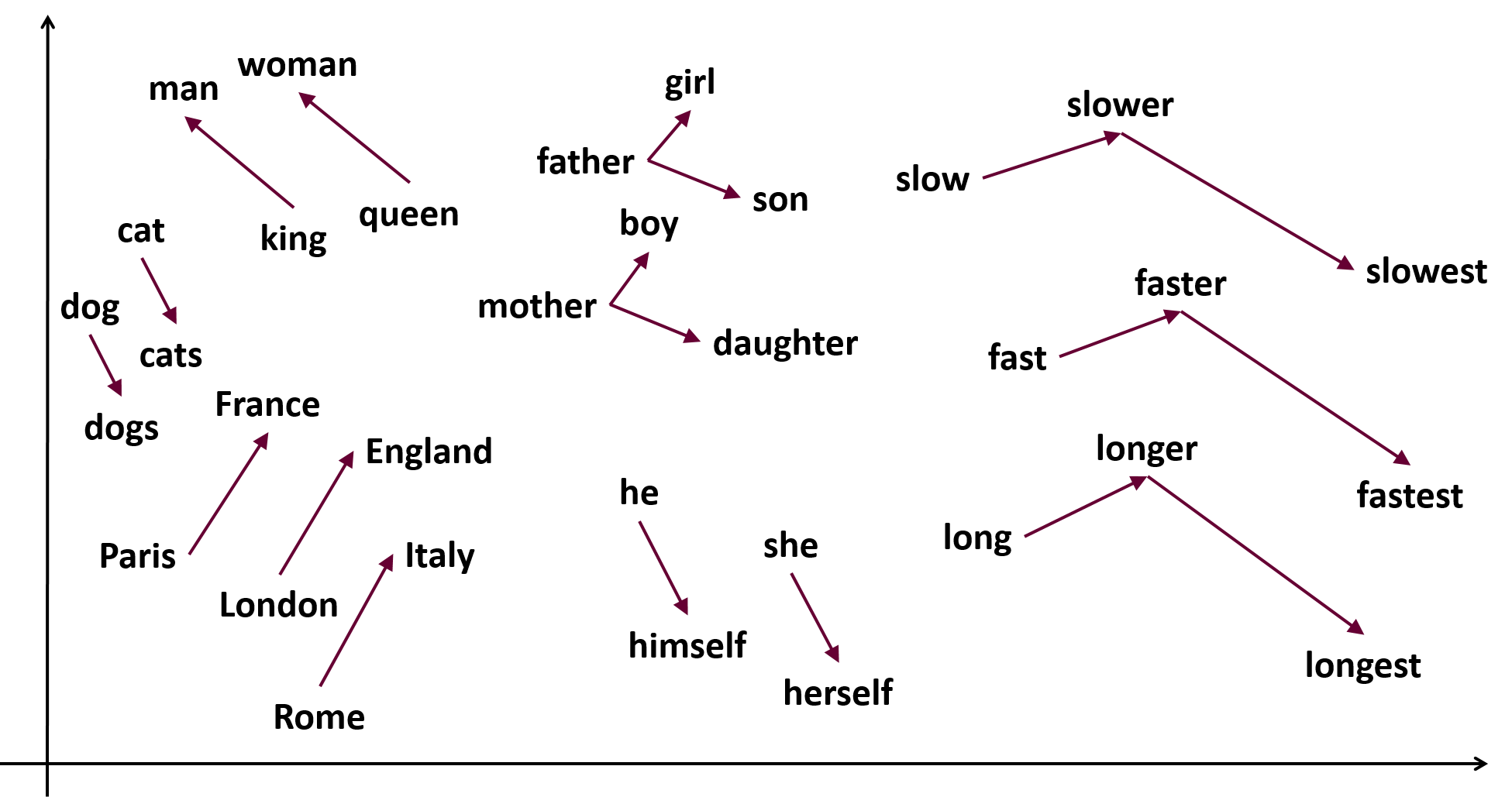
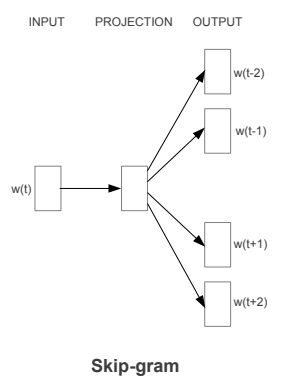
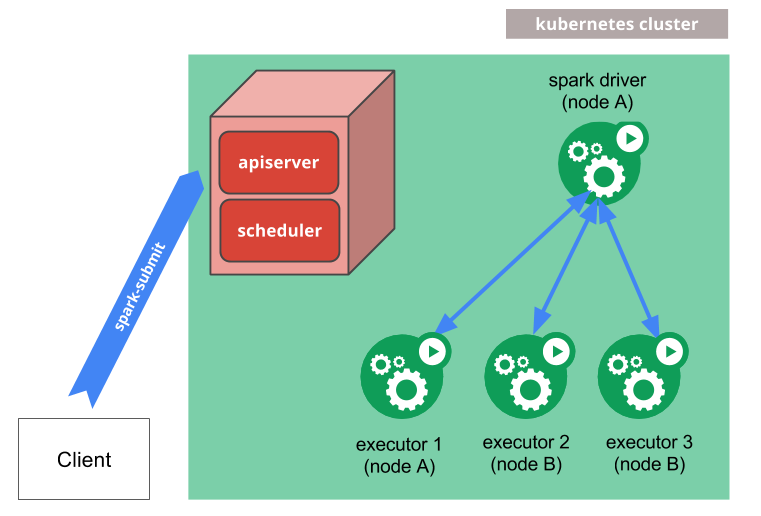
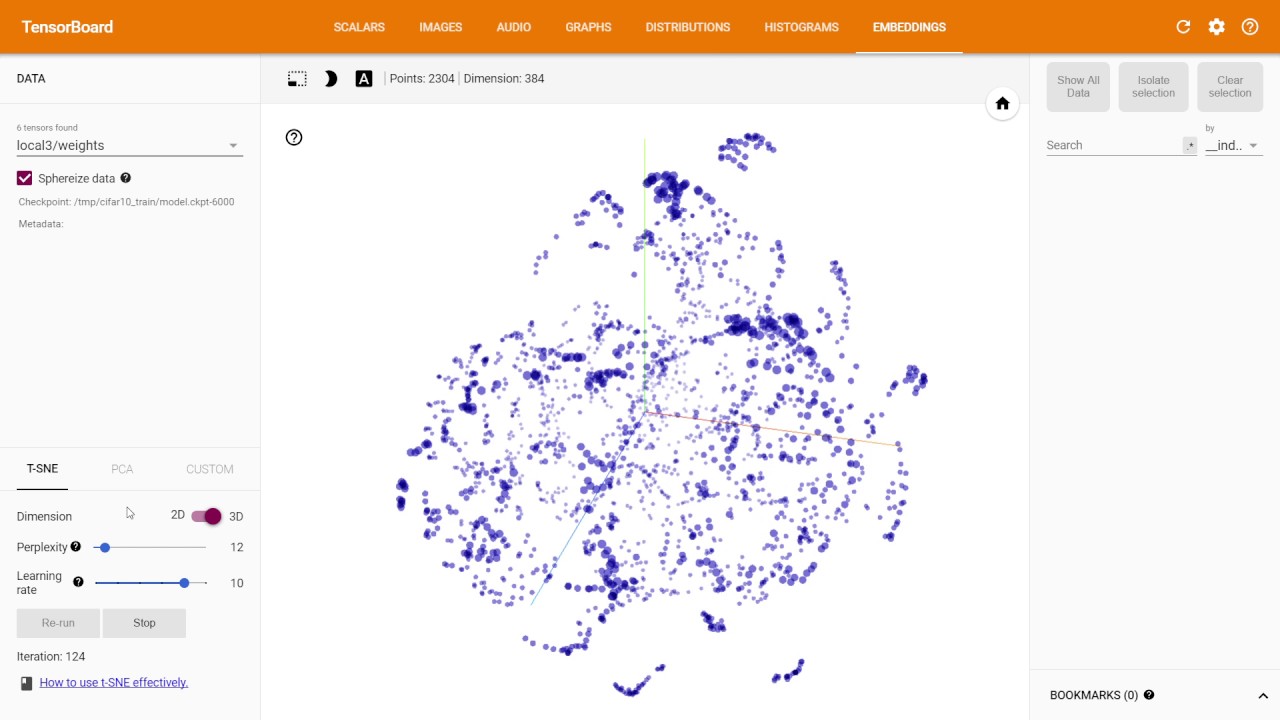
Curate Solutions scrapes through minutes and agenda documents from local meetings of hundreds of counties across the country each week. The Madison based startup scans through the collected data using a mixture of machine learning/language processing models and a human data analysis team to retrieve information valuable to customers. Customers may include construction companies looking for new projects to bid on etc. During my time at the company, I worked on building, training and deploying machine learning models on large scale textual datasets to extract data valuable to customers.
- Time period: May 2018 - May 2019
- Location: Madison, WI