Esri - Geographic information system company
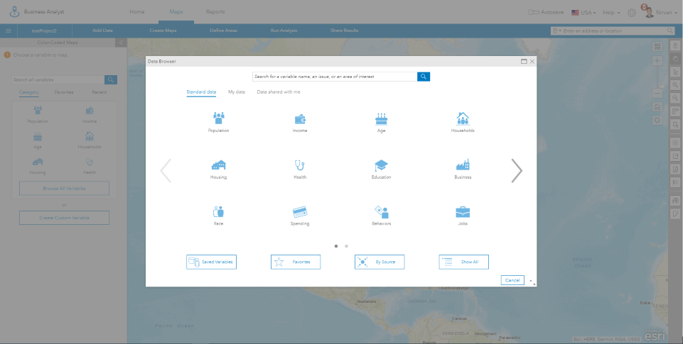
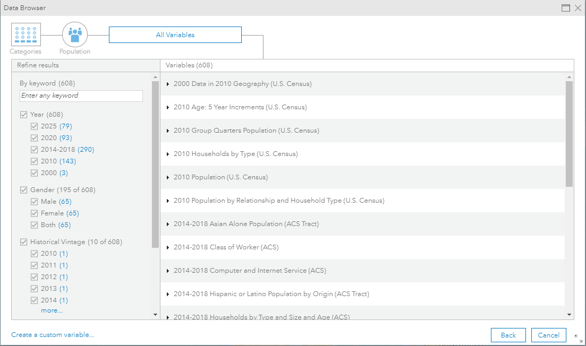
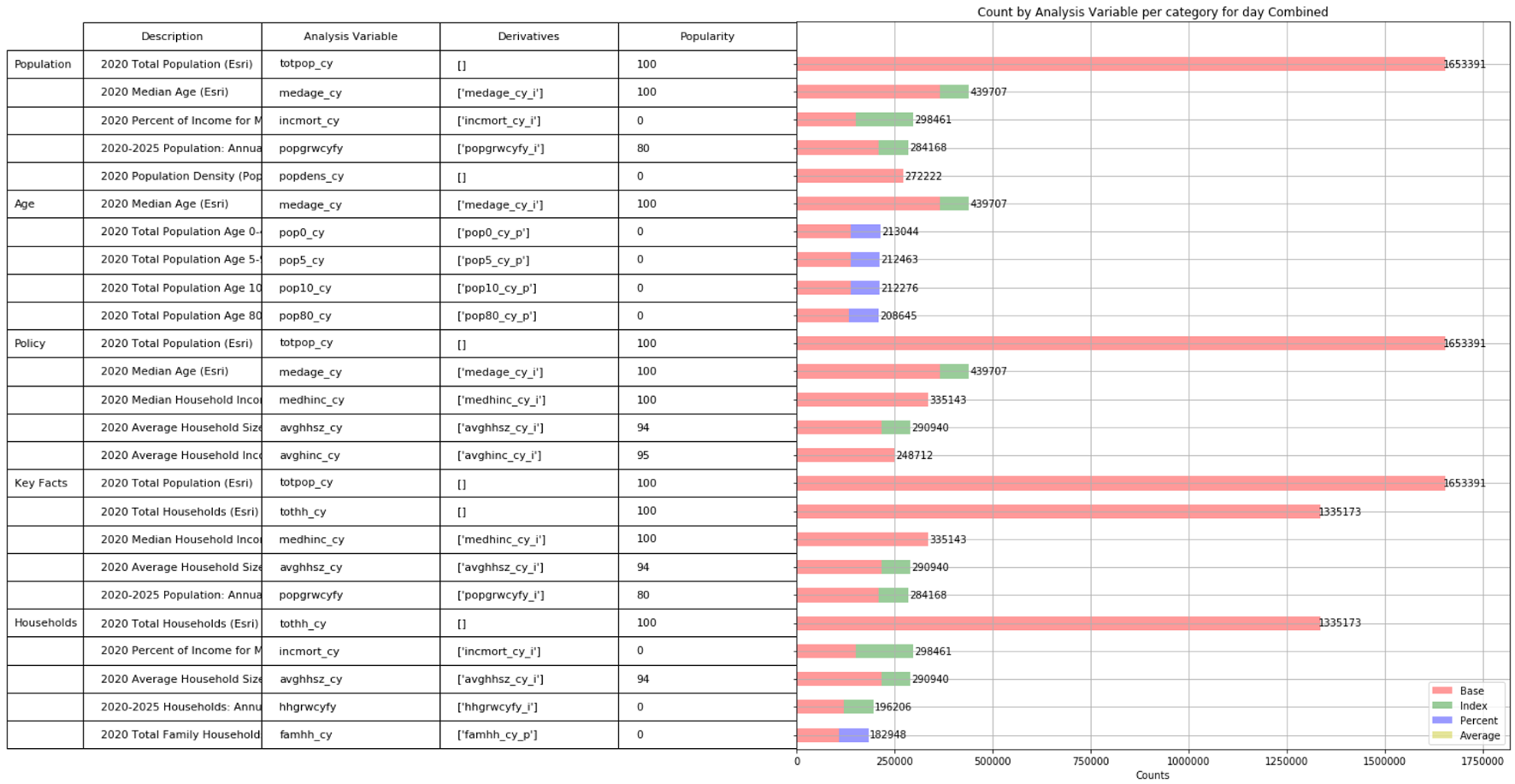
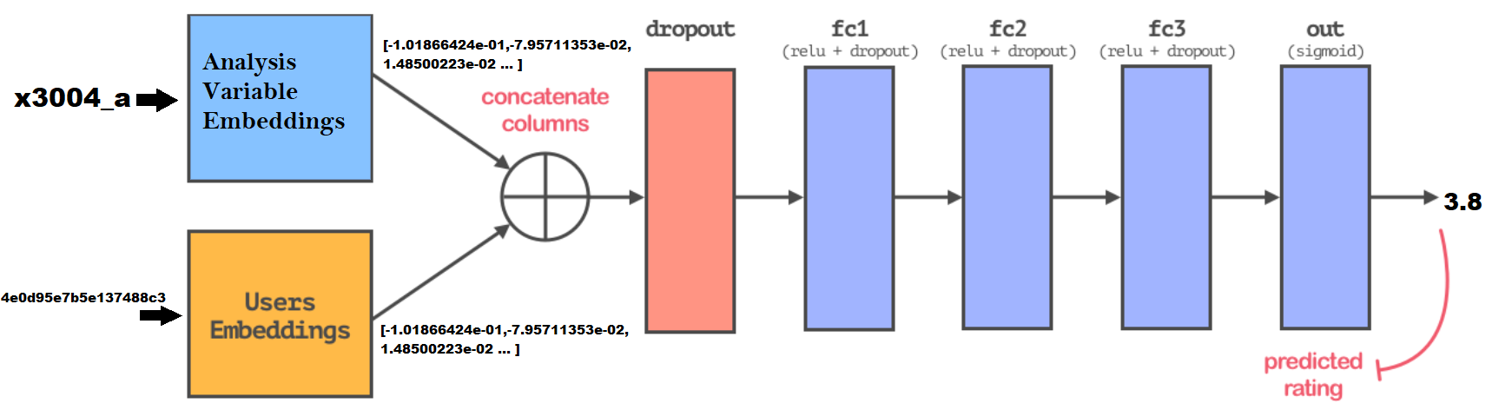
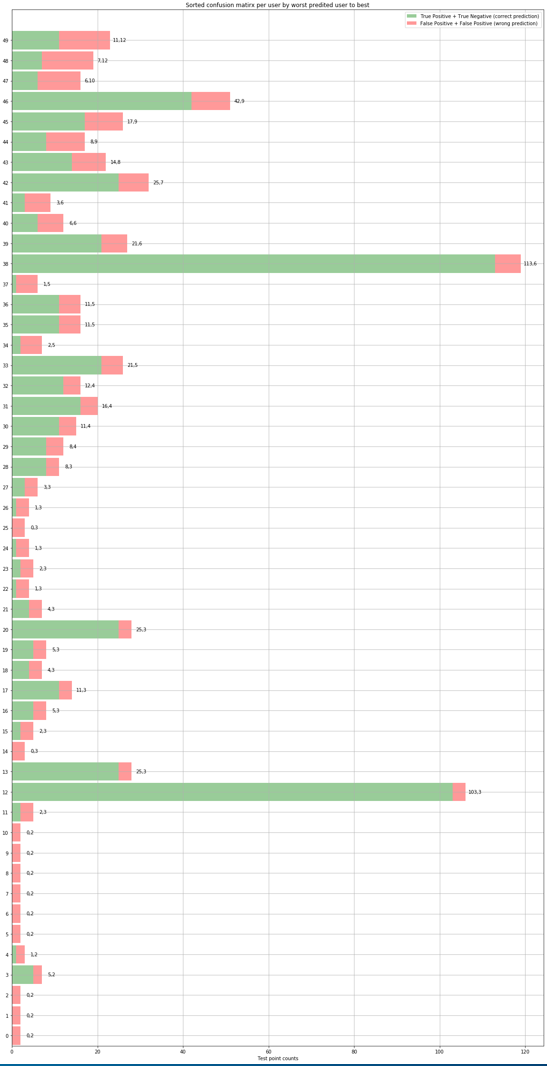
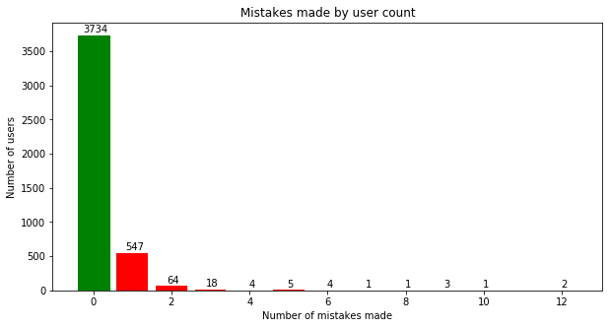
Esri is an international supplier of geographic information system software, web GIS and geodatabase management applications. During my summer internship, I worked for the Business Analyst Team. My summer project on the team involved finding a way to improve the data browser that presented a plethora of available datasets to the user which could be overwhelming at times. This problem was solved by building a framework to recommend or order the list of datasets based on historical usage statistics.
- Time period: June 2020 - August 2020
- Location: Redlands, CA