GeoGuessr AI: Image based geo-location
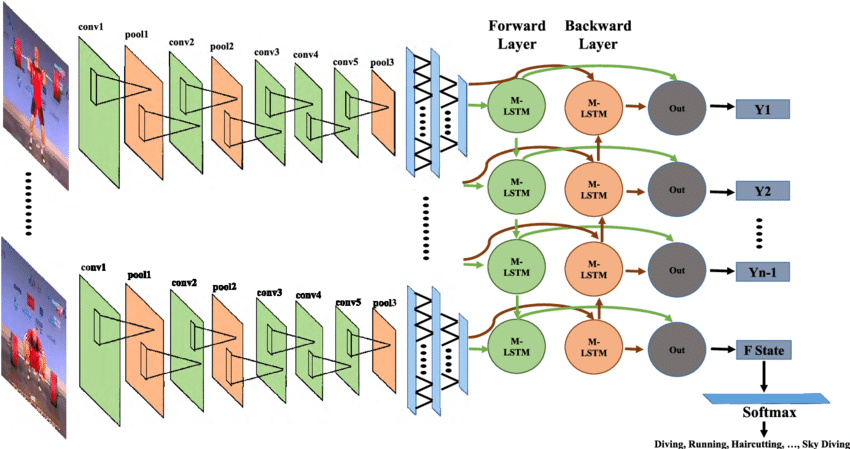
This project was done for the Neural Networks and Deep Learning at University of Colorado Boulder. Geolocation is the estimation of real-world geographic location using location based data. The motivation for this project came form the game called GeoGuessr, where users are presented with the Google street view of a location and asked to predict the location as best as they can. A custom CNN/LSTM neural network was used to accomplish the task of image based GeoLocation using artificial intelligence.
- Time period: March 2020 - May 2020
- Project Type: Class project (CSCI 5922)
- Documentation: GeoGuessr AI: Image based geo-location
- Github: GeoGuessr AI