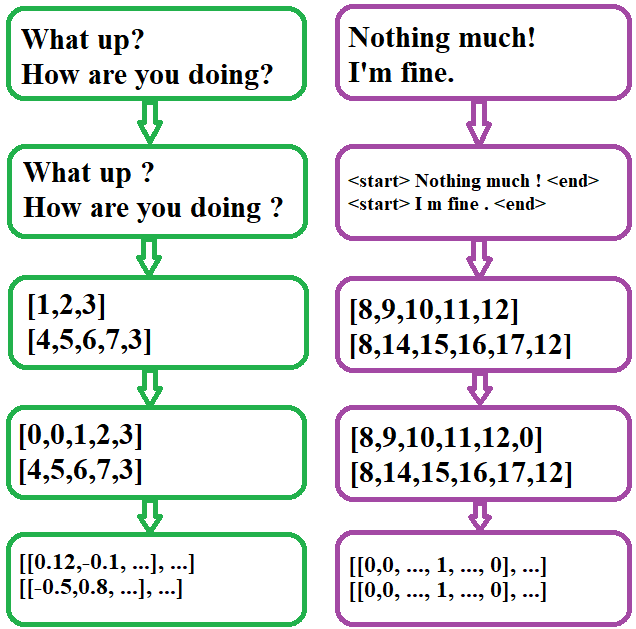
Preprocessed and vectorized statement response pairs.
The dialogs were broken into words and punctuation mark. A word here does not have to reference and actual English word but a maximal sequence of characters excluding punctuation marks and white space. Punctuation marks were treated as individual tokens in an attempt to help the model to better understand questions, statements and commands. Numeric data was removed to reduce vocabulary sized and start and end tokens were added responses.
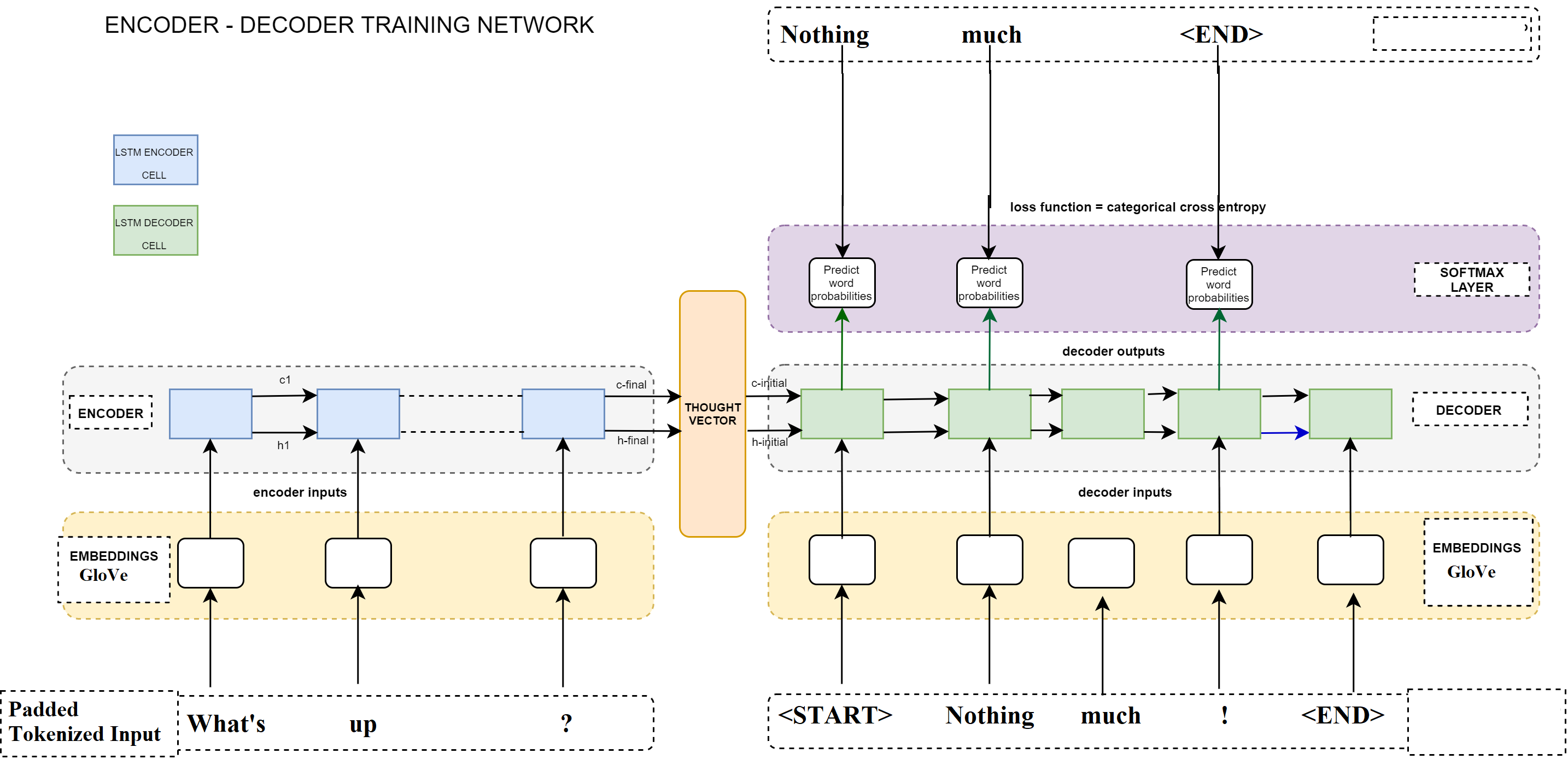
To make the above data ingestible for the embedding layer of the model, every word, punctuation mark and tag was mapped to a numeric token. The Tokenizer consumes the entire corpus to create this mapping which is then applied to every statement and response in the dataset to create a collection of input and output sequence pairs.
The next was Padding the tokenized sequences with zeroes so they all have the same size. The input sequences were pre padded while the output was post padded.
Next, every token in the sequence had to be given a unique vector representation. This was handle by the Embedding Layer. To provide contextual representations of tokens (words, punctuation marks and tags), GloVe 300-dimensional word embeddings were used to initialized the embedding layer weights.
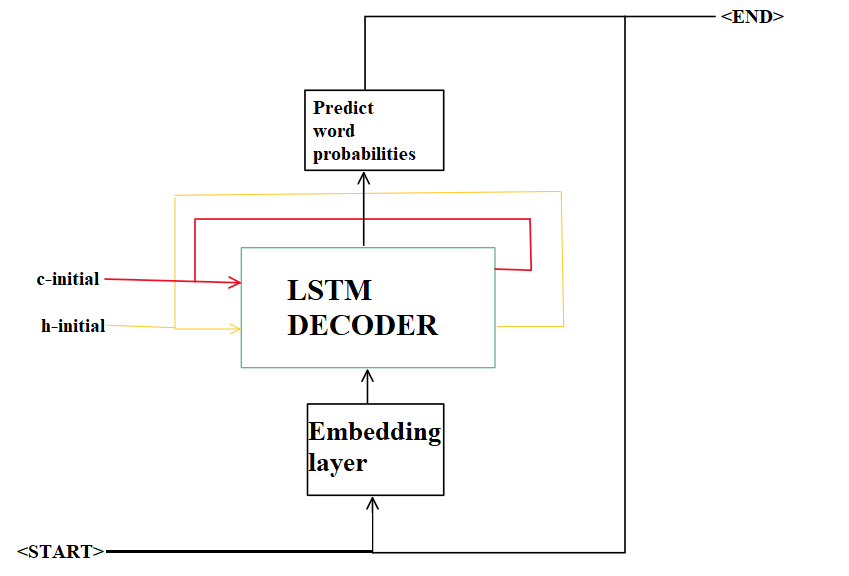
Since the model outputs a softmaxed prediction on each token, the next step involved converting output tokens to one-hot vectors. Since the goal of the decoder was to predict the next token given the current token, the tokenized output sequence was shifted to the left by one step before being converted to one-hot vectors.